Les relations littéraires entre la France et la Hongrie au XXe siècle
Le projet implique la création d'une base de données textuelle des lettres conservées dans plusieurs collections publiques et privées hongroises.
Le projet a démarré en octobre 2016 à l’Institut d’Études Littéraires, Centre de Recherches en Sciences Humaines de l’Académie des Sciences de Hongrie par le biais de la bourse post-doctorale de l’Office national de la recherche, du développement et de l'innovation et sera terminé en septembre 2019. La base de données contient actuellement environ 2400 lettres.
Il a été mis en œuvre à travers 5 étapes :
1. identification des lettres publiées et non publiées dans la base de données et constituant un corpus organique. Ces collections publiques et privées sont :
- Département des Manuscrits du Musée Littéraire Petőfi (1450 documents)
- Département des Manuscrits de la Bibliothèque nationale Széchényi (100 documents) - Archives de l’Institut d’Études Littéraires Centre de Recherches en Sciences Humaines de l’Académie des Sciences de Hongrie (100 documents) - Département des Manuscrits de la Bibliothèque et Centre d'Information de l'Académie des Sciences de Hongrie (100 documents)
- Fondation József Károlyi, Fehérvárcsurgó (50 documents)
- collection privée de l’héritage de l'écrivain Endre Bajomi Lázár (500 documents)
- collection privée de l’héritage de l'écrivain Gyula Illyés (100 documents)
2. lettres manuscrites - pas d’opérations OCR mais déchiffrer et dactylographier manuellement
3. la création d'une base de données de tous les textes, avec la possibilité de rechercher
4. l'identification et l'indexation de noms de personnes et d’institutions
5. visualiser et rechercher pour le web
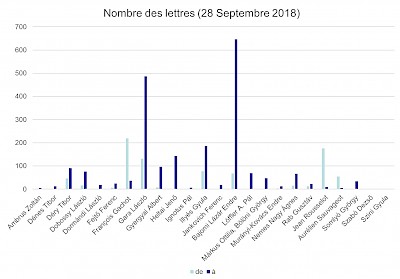
Le corpus comprend la correspondance de vingt-cinq personnages et de plusieurs autres héritages mineurs du point de vue des relations littéraires franco-hongroises :
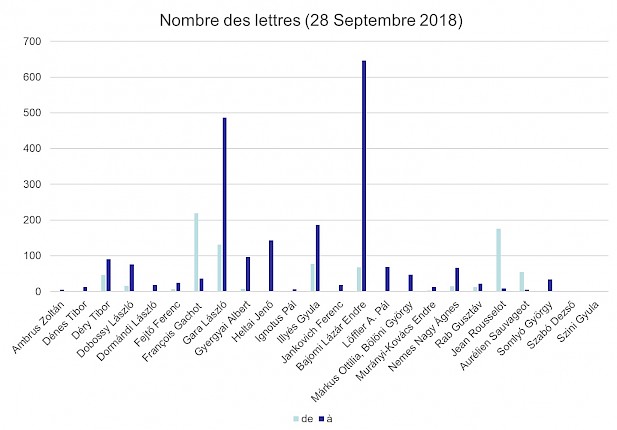
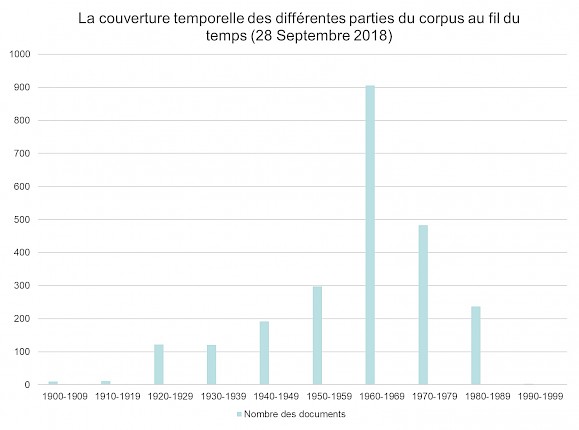
Quelques données :
Le projet a produit un corpus de correspondance indexé. J'ai mis les documents dans une base de données en PHP, basée sur le framework ProcessWire gratuit. Elle est conforme à la norme TEI XML, dans une version spécialement dédiée au corpus.
Le corpus comprend actuellement:
8 collections publiques et privées
30 personnes majeures de la vie littéraire
2400 lettres, dont 300 sont publiées et 2100 non publiées jusqu’ici
1000 lettres indexées jusqu’ici
1800 noms de personnes et d’institutions
Directions de la recherche : Anna Tüskés (Institut d’Études Littéraires, Centre de Recherches en Sciences Humaines, Académie des Sciences de Hongrie)
Développement de la base de données : Tamás Mészáros (Université de technologie et d'économie de Budapest)